一致性内核(Consistent Core)
问题
在集群内部中存在部分数据(节点信息、数据分片信息等)需要保证强一致性(线性一致性),通常的方案是使用quorum写入方式,但是其系统的吞会随着节点的增加降低。
解决方案
集群内部再组建一个3或5个节点的小集群,通过relase机制在集群内部进行决策。最简单的接口如下:
public interface ConsistentCore {
CompletableFuture put(String key, String value);
List<String> get(String keyPrefix);
CompletableFuture registerLease(String name, long ttl);
void refreshLease(String name);
void watch(String name, Consumer<WatchEvent> watchCallback);
}
元数据存储
可以基于raft来存储
客户端交互
所有的操作都要在领导者上执行,这是至关重要的,因此,客户端程序库需要先找到领导者服务器。要做到这一点,有两种可能的方式:
- 一致性内核的追随者服务器知道当前的领导者,因此,如果客户端连接追随者,它会返回 领导者的地址。客户端可以直接连接应答中给出的领导者。值得注意的是,客户端尝试连接时,服务器可能正处于领导者选举过程中。在这种情况下,服务器无法返回领导者地址,客户端需要等待片刻,再尝试连接另外的服务器。
- 服务器实现转发机制,将所有的客户端请求转发给领导者。这样就允许客户端连接任意的服务器。同样,如果服务器处于领导者 选举过程中,客户端需要不断重试,直到领导者选举成功,一个合法的领导者获得确认。
追随者读取(Follower Reads)
问题
使用领导者和追随者模式时,如果有太多请求发给领导者,它可能会出现过载。此外,在多数据中心的情况下,客户端如果在远程的数据中心,向领导者发送的请求可能会有额外的延迟。
解决方案
当写请求要到领导者那去维持一致性,只读请求就会转到最近的追随者。当客户端大多都是只读的,这种做法就特别有用。但是,从追随者那里读取的客户端得到可能是旧值。对于该问题有2种解决方法:
- 追随者发现自己和领导者之间滞后的数据量比较大时,会返回一个错误给client,client收到此错误的时候会自动连领导者进行读取
- 每条数据写入时会生成对应的版本戳,这个版本戳可以是高水位标记(High-Water Mark)或是混合时钟(Hybrid Clock)。然后,如果客户端希望稍后读取该值的话,它就把这个版本戳当做读取请求的一部分。如果读取请求到了追随者那里,它就会检查其存储的值,看它是等于或晚于请求的版本戳。如果不是,它就会等待,直到有了最新的版本,再返回该值。通过这种做法,这个客户端总会读取与它写入一直的值——这种做法通常称为“读自己写”的一致性。
Lamport 时钟(Lamport Clock)
问题
当值要在多个服务器上进行存储时,需要有一种方式知道一个值要在另外一个值之前存储。在这种情况下,不能使用系统时间戳,因为时钟不是单调的,两个服务器的时钟时间不应该进行比较。
解决方案
class LamportClock…
public int tick(int requestTime) {
latestTime = Integer.max(latestTime, requestTime);
latestTime++;
return latestTime;
}
class Server…
public int write(String key, String value, int requestTimestamp) {
//update own clock to reflect causality
int writeAtTimestamp = clock.tick(requestTimestamp);
mvccStore.put(new VersionedKey(key, writeAtTimestamp), value);
return writeAtTimestamp;
}
用于写入值的时间戳会返回给客户端。通过更新自己的时间戳,客户端会跟踪最大的时间戳。它在发出进一步写入请求时会使用这个时间戳。
class Client…
LamportClock clock = new LamportClock(1);
public void write() {
int server1WrittenAt = server1.write("name", "Alice", clock.getLatestTime());
clock.updateTo(server1WrittenAt);
int server2WrittenAt = server2.write("title", "Microservices", clock.getLatestTime());
clock.updateTo(server2WrittenAt);
assertTrue(server2WrittenAt > server1WrittenAt);
}
每个集群节点都维护着一个 Lamport 时钟的实例,服务器每当进行任何写操作时,服务器都应该让 Lamport 时钟前进。如此一来,服务器可以确保写操作的顺序是在这个请求之后,以及客户端发起请求时服务器端已经执行的任何其他动作之后。服务器会返回一个时间戳,用于将值写回给客户端。稍后,请求的客户端会使用这个时间戳向其它的服务器发起进一步的写操作。如此一来,请求的因果链就得到了维持。但是只能保证部分有序,对于在不同server上的数据无法比较
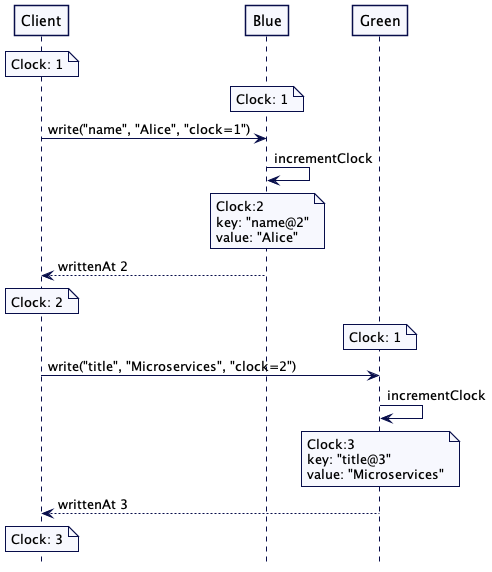
单一服务器/领导者更新值
只有领导者负责递增版本计数器,追随者使用相同的版本号。
领导者和追随者(Leader and Followers)
问题
当数据在多个服务器上更新时,需要决定何时让客户端看到这些数据。只有写读的Quorum是不够的,因为一些失效的场景会导致客户端看到不一致的数据。单个的服务器并不知道Quorum上其它服务器的数据状态,只有数据是从多台服务器上读取时,才能解决不一致的问题。在某些情况下,这还不够。发送给客户端的数据需要有更强的保证。
解决方案
在集群里选出一台服务器成为领导者。领导者负责根据整个集群的行为作出决策,并将决策传给其它所有的服务器。
领导者选举
只有“最新”的服务器才能成为合法的领导者。比如说,在典型的基于共识的系统中,“最新”由两件事定义:
- 最新的世代时钟(Generation Clock)
- 预写日志(Write-Ahead Log)的最新日志索引
如果所有的服务器都是最新的,领导者可以根据下面的标准来选:
- 一些实现特定的标准,比如,哪个服务器评级为更好或有更高的 ID(比如,Zab)
- 如果要保证注意每台服务器一次只投一票,就看哪台服务器先于其它服务器启动选举
使用外部[线性化]的存储进行领导者选举
在一个数据集群内运行领导者选举,对小集群来说,效果很好。但对那些有数千个节点的大数据集群来说,使用外部存储会更容易一些,比如 Zookeeper 或 etcd (其内部使用了共识,提供了线性化保证)。实现领导者选举要有三个功能:
- compareAndSwap 指令,能够原子化地设置一个键值
- 心跳的实现,如果没有从选举节点收到心跳,将键值做过期处理,以便触发新的选举
- 通知机制,如果一个键值过期,就通知所有感兴趣的服务器
世代时钟(Generation Clock)
问题
集群余下的部分要能检测出有的请求是来自原有的领导者。原有的领导者本身也要能检测出,它是临时从集群中断开了,然后,采用必要的修正动作,交出领导权。
解决方案
维护一个单调递增的数字,表示服务器的世代。每次选出新的领导者,这个世代都应该递增。即便服务器重启,这个世代也应该是可用的,因此,它应该存储在预写日志(Write-Ahead Log)每一个条目里
采用领导者和追随者(Leader and Followers)模式,选举新的领导者选举时,服务器对这个世代的值进行递增。
class ReplicationModule…
private void startLeaderElection() {
replicationState.setGeneration(replicationState.getGeneration() + 1);
registerSelfVote();
requestVoteFrom(followers);
}
服务器会把世代当做投票请求的一部分发给其它服务器。在这种方式下,经过了成功的领导者选举之后,所有的服务器都有了相同的世代。一旦选出新的领导者,追随者就会被告知新的世代。
follower
class ReplicationModule
private void becomeFollower(int leaderId, Long generation) {
replicationState.setGeneration(generation);
replicationState.setLeaderId(leaderId);
transitionTo(ServerRole.FOLLOWING);
}
自此之后,领导者会在它发给追随者的每个请求中都包含这个世代信息。它也包含在发给追随者的每个心跳(HeartBeat)消息里,也包含在复制请求中。领导者也会把世代信息持久化到预写日志(Write-Ahead Log)的每一个条目里,如果追随者得到了一个来自已罢免领导的消息,追随者就可以告知其世代过低。当领导者得到了一个失败的应答,它就会变成追随者,期待与新的领导者建立通信。
混合时钟
问题
采用有版本的值(Versioned Value)时,如果用 Lamport 时钟当做版本,存储版本时,客户端并不知道实际的日期-时间。对于客户端而言,有时需要能够访问到像 01-01-2020 这样采用日期-时间的版本,而不仅仅是像 1、2、3 这样的整数。
解决方案
混合时间戳里维护了最新的时间,这个时间戳使用系统时间和整数计数器共同构建
class HybridTimestamp…
public class HybridTimestamp implements Comparable<HybridTimestamp> {
private final long wallClockTime;
private final int ticks;
public HybridTimestamp(long systemTime, int ticks) {
this.wallClockTime = systemTime;
this.ticks = ticks;
}
public static HybridTimestamp fromSystemTime(long systemTime) {
return new HybridTimestamp(systemTime, -1); //initializing with -1 so that addTicks resets it to 0
}
public HybridTimestamp max(HybridTimestamp other) {
if (this.getWallClockTime() == other.getWallClockTime()) {
return this.getTicks() > other.getTicks()? this:other;
}
return this.getWallClockTime() > other.getWallClockTime()?this:other;
}
public long getWallClockTime() {
return wallClockTime;
}
public HybridTimestamp addTicks(int ticks) {
return new HybridTimestamp(wallClockTime, this.ticks + ticks);
}
public int getTicks() {
return ticks;
}
@Override
public int compareTo(HybridTimestamp other) {
if (this.wallClockTime == other.wallClockTime) {
return Integer.compare(this.ticks, other.ticks);
}
return Long.compare(this.wallClockTime, other.wallClockTime);
}
}
public synchronized HybridTimestamp now() {
long currentTimeMillis = systemClock.currentTimeMillis();
if (latestTime.getWallClockTime() >= currentTimeMillis) {
//检查系统时间值是否在往回走,如果是,则递增另一个代表组件逻辑部分的数字,以反映时钟的进展。
latestTime = latestTime.addTicks(1);
} else {
latestTime = new HybridTimestamp(currentTimeMillis, 0);
}
return latestTime;
}
服务器从客户端收到的每个写请求都会带有一个时间戳。接收的服务器会将自己的时间戳与请求的时间戳进行比较,将二者中较高的一个设置为自己的时间戳。
public HybridTimestamp write(String key, String value, HybridTimestamp requestTimestamp) {
//update own clock to reflect causality
HybridTimestamp writeAtTimestamp = clock.tick(requestTimestamp);
mvccStore.put(key, writeAtTimestamp, value);
return writeAtTimestamp;
}
class HybridClock…
public synchronized HybridTimestamp tick(HybridTimestamp requestTime) {
long nowMillis = systemClock.currentTimeMillis();
//set ticks to -1, so that, if this is the max, the next addTicks reset it to zero.
HybridTimestamp now = HybridTimestamp.fromSystemTime(nowMillis);
latestTime = max(now, requestTime, latestTime);
latestTime = latestTime.addTicks(1);
return latestTime;
}
private HybridTimestamp max(HybridTimestamp ...times) {
HybridTimestamp maxTime = times[0];
for (int i = 1; i < times.length; i++) {
maxTime = maxTime.max(times[i]);
}
return maxTime;
}
用于写入值的时间戳会返回给客户端。请求的客户端会更新自己的时间戳,然后,在发起进一步的写入时会带上这个时间戳。
HybridClock clock = new HybridClock(new SystemClock());
public void write() {
HybridTimestamp server1WrittenAt = server1.write("key1", "value1", clock.now());
clock.tick(server1WrittenAt);
HybridTimestamp server2WrittenAt = server2.write("key2", "value2", clock.now());
assertTrue(server2WrittenAt.compareTo(server1WrittenAt) > 0);
}
幂等接收者(Idempotent Receiver)
问题
如果服务器已经处理了请求,然后奔溃了,之后,客户端重试时,服务器端会收到客户端的重复请求。
解决方案
- 每个客户端都会收到一个唯一的ID,同时client会保存一个计数器,为每个请求也会分配一个ID
- 服务器会为每个client创建一个session,保存对应client的请求信息
- 对于过期的请求, 1)保存处理成功的最大的请求ID,该ID也会转发给其他的服务器,小于该ID的请求都丢掉 2)如果client侧能保证收到上一个请求的response之后才能发送下一个request,则服务器一旦收到这个client的请求可以丢掉之前的所有请求
Gossip 传播(Gossip Dissemination)
问题
在拥有多个节点的集群中,每个节点都要向集群中的所有其它节点传递其所拥有的元数据信息,无需依赖于共享存储。
解决方案
每个集群节点都会调度一个 job 用以定期将其拥有的元数据传输给其他节点,调用调度任务时,它会从元数据集合的服务器列表中随机选取一小群节点。对于接收 Gossip 消息的集群节, 会做以下三件事:
- 传入消息中的值,且不再该节点状态集合中的消息,会merge到本地内存中
- 该节点拥有,但不再传入的 Gossip 消息中的消息,会返回给请求发送方,其会merge到本地内存中
- 节点拥有传入消息的值,这时会选择版本更高的值
心跳(HeartBeat)
问题
解决方案
一个服务器周期性地发送请求给所有其它的服务器,以此表明它依然活跃。选择的请求间隔应该大于服务器间的网络往返的时间。所有的服务器在检查心跳时,都要等待一个超时间隔,超时间隔应该是多个请求间隔。通常来说,超时间隔 > 请求间隔 > 服务器间的网络往返时间
小集群
在所有的共识实现中,心跳是从领导者服务器发给所有追随者服务器的。每次收到心跳,都要记录心跳到达的时间戳。如果固定的时间窗口内没有收到心跳,就可以认为领导者崩溃了,需要选出一个新的服务器成为领导者
大集群
给每个进程分配一个怀疑计数,在限定的时间内,如果没有收到该进程的 Gossip 消息,则怀疑计数递增。它可以根据过去的统计信息计算出来,只有在这个怀疑计数到达配置的上限时,才将其标记为失效。
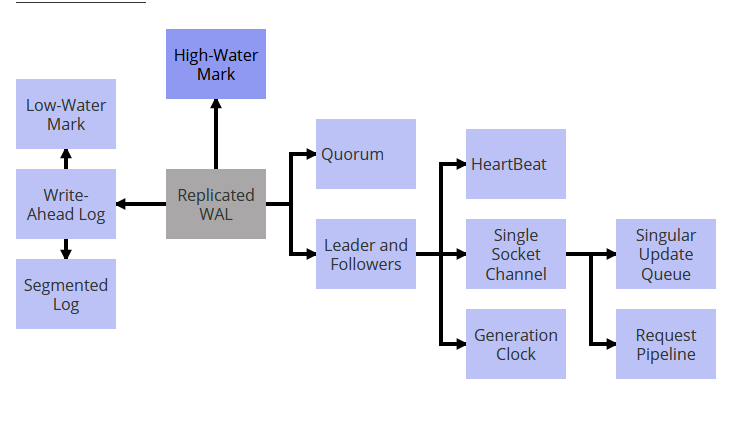
高水位标记(High-Water Mark)
问题
如果领导者失效了,集群会选出一个新的领导者,客户端在大部分情况下还是能像从前一样继续在集群中工作。但是,还有几件事可能会有问题:
- 在向任意的追随者发送日志条目之前,领导者失效了
- 一部分追随者发送日志条目之后,领导者失效了,日志条目没有发送给大部分的追随者
在这些错误的场景下,一部分追随者的日志中可能会缺失一些条目,一部分追随者则拥有比其它部分多的日志条目。因此,对于每个追随者来说,有一点变得很重要,了解日志中哪个部分是安全的,对客户端是可用的。
解决方案
高水位标记就是一个日志文件中的索引,记录了在追随者的 Quorum 中都成功复制的最后一个日志条目。在复制期间,领导者也会把高水位标记传给追随者。对于集群中的所有服务器而言,只有反映的更新小于高水位标记的数据才能传输给客户端。
- 对于每个日志条目而言,领导者将其追加到本地的预写日志中,然后,发送给所有的追随者。追随者会处理复制请求,将日志条目追加到本地日志中。在成功地追加日志条目之后,它们会把最新的日志条目索引回给领导者。应答中还包括服务器当前的时代时钟(Generation Clock)。
- 领导者通过查看所有追随者的日志索引和领导者自身的日志,高水位标记是可以计算出来的,选取大多数服务器中可用的索引即可。
- 领导者会将高水位标记传播给追随者,可能是当做常规心跳的一部分,也可能一个单独的请求。追随者随后据此设置自己的高水位标记。客户端只能读取到高水位标记前的日志条目。超出高水位标记的对客户端是不可见的。
日志截断
暂停之后,重新启动或是重新加入集群,服务器都会先去寻找新的领导者。然后,它会显式地查询当前的高水位标记,将日志截断至高水位标记,然后,从领导者那里获取超过高水位标记的所有条目。类似 RAFT 之类的复制算法有一些方式找出冲突项,比如,查看自己日志里的日志条目,对比请求里的日志条目。如果日志条目拥有相同的索引,但时代时钟(Generation Clock)更低的话,就删除这些条目
租约(Lease)
问题
集群节点需要对特定的资源进行排他性访问。但是,节点可能会崩溃;他们会临时失联,经历进程暂停。在这些出错的场景下,它们不应该无限地保持对资源的访问。
解决方案
- 集群节点可以申请一个有时间限制的租约,超过时间就过期。
- 拥有租约的节点负责定期刷新它。心跳(HeartBeat)就是客户端用来更新在一致性内核中的存活时间值的。
- 用一致性内核(Consistent Core)实现租约机制,租约可以在领导者和追随者(Leader and Followers)之间复制,以提供兼容性和一致性。
- 一致性内核(Consistent Core)中的所有节点都可以创建租约,但只有领导者要追踪租约的超时时间。一致性内核的追随者不用追踪超时时间,这么做是因为领导者要用自己的单调时钟决定租约何时过期。
- 当既有的领导者失效了,一致性内核(Consistent Core)会选出一个新的领导者。一旦当选,新的领导者就要开始追踪租约。新的领导者会刷新它所知道的所有租约。请注意,原有领导者上即将过期的租约会延长一个“存活时间”的值。
class LeaderLeaseTracker{
private ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1);
private ScheduledFuture<?> scheduledTask;
private Map<String, Lease> leases;
@Override
public void start() {
scheduledTask = executor.scheduleWithFixedDelay(this::checkAndExpireLeases,
leaseCheckingInterval,
leaseCheckingInterval,
TimeUnit.MILLISECONDS);
}
@Override
public void checkAndExpireLeases() {
remove(expiredLeases());
}
private void remove(Stream<String> expiredLeases) {
expiredLeases.forEach((leaseId)->{
//remove it from this server so that it doesnt cause trigger again.
expireLease(leaseId);
//submit a request so that followers know about expired leases
submitExpireLeaseRequest(leaseId);
});
}
private Stream<String> expiredLeases() {
long now = System.nanoTime();
Map<String, Lease> leases = kvStore.getLeases();
return leases.keySet().stream()
.filter(leaseId -> {
Lease lease = leases.get(leaseId);
return lease.getExpiresAt() < now;
});
}
@Override
public void addLease(String name, long ttl) throws DuplicateLeaseException {
//有一点需要注意,在哪里验证租约注册是否重复。在提出请求之前检查是不够的,因为可能会存在多个在途请求。因此,服务器要在成功复制之后,它还要检查租约注册是否重复。
if (leases.get(name) != null) {
throw new DuplicateLeaseException(name);
}
Lease lease = new Lease(name, ttl, clock.nanoTime());
leases.put(name, lease);
}
@Override
public void refreshLease(String name) {
//租约时间过半时发送请求。这样一来,在租约时间内,最多发送两次刷新请求。客户端节点可以用自己的单调时钟来跟踪时间。
Lease lease = leases.get(name);
lease.refresh(clock.nanoTime());
}
public void expireLease(String name) {
getLogger().info("Expiring lease " + name);
Lease removedLease = leases.remove(name);
removeAttachedKeys(removedLease);
}
}
低水位标记(Low-Water Mark)
问题
预写日志维护着持久化存储的每一次更新。随着时间的推移,它会无限增长。使用分段日志,一次可以处理更小的文件,但如果不检查,磁盘总存储量会无限增长。
解决方案
基于快照的低水位标记
存储引擎会周期地打快照,已经成功应用的日志索引也要和快照一起存起来,快照一旦持久化到磁盘上,日志管理器就会得到低水位标记,之后,就可以丢弃旧的日志了。
public SnapShot takeSnapshot() {
Long snapShotTakenAtLogIndex = wal.getLastLogEntryId();
return new SnapShot(serializeState(kv), snapShotTakenAtLogIndex);
}
List<WALSegment> getSegmentsBefore(Long snapshotIndex) {
List<WALSegment> markedForDeletion = new ArrayList<>();
List<WALSegment> sortedSavedSegments = wal.sortedSavedSegments;
for (WALSegment sortedSavedSegment : sortedSavedSegments) {
if (sortedSavedSegment.getLastLogEntryId() < snapshotIndex) {
markedForDeletion.add(sortedSavedSegment);
}
}
return markedForDeletion;
}
基于时间的低水位标记
private List<WALSegment> getSegmentsPast(Long logMaxDurationMs) {
long now = System.currentTimeMillis();
List<WALSegment> markedForDeletion = new ArrayList<>();
List<WALSegment> sortedSavedSegments = wal.sortedSavedSegments;
for (WALSegment sortedSavedSegment : sortedSavedSegments) {
if (timeElaspedSince(now, sortedSavedSegment.getLastLogEntryTimestamp()) > logMaxDurationMs) {
markedForDeletion.add(sortedSavedSegment);
}
}
return markedForDeletion;
}
private long timeElaspedSince(long now, long lastLogEntryTimestamp) {
return now - lastLogEntryTimestamp;
}
单一 Socket 通道(Single Socket Channel)
问题
使用领导者和追随者(Leader and Followers)时,我们需要确保在领导者和各个追随者之间的消息保持有序,如果有消息丢失,需要重试机制。
解决方案
幸运的是,已经长期广泛使用的 TCP 机制已经提供了所有这些必要的特征。因此,我们只要确保追随者与其领导者之间都是通过单一的 Socket 通道进行通信,就可以进行我们所需的通信。然后,追随者再对来自领导者的更新进行序列化,将其送入单一更新队列(Singular Update Queue)。
有一点很重要,就是连接要有超时时间,这样就不会在出错的时候,造成永久阻塞了。我们使用心跳(HeartBeat)周期性地在 Socket 通道上发送请求,以便保活。超时时间通常都是多个心跳的间隔,这样,网络的往返时间以及可能的一些延迟就不会造成问题了
通过单一通道发送请求,可能会带来一个问题,也就是队首阻塞(Head-of-line blocking,HOL)问题。为了避免这个问题,我们可以使用请求管道(Request Pipeline)。
请求管道(Request Pipeline)
问题
在集群里服务器间使用单一 Socket 通道(Single Socket Channel)进行通信,如果一个请求需要等到之前请求对应应答的返回,这种做法可能会导致性能问题。为了达到更好的吞吐和延迟,服务端的请求队列应该充分填满,确保服务器容量得到完全地利用。比如,当服务器端使用了单一更新队列(Singular Update Queue),只要队列未填满,就可以继续接收更多的请求。如果只是一次只发一个请求,大多数服务器容量就毫无必要地浪费了。
解决方案
节点向另外的节点发送请求,无需等待之前请求的应答。只要创建两个单独的线程就可以做到,一个在网络通道上发送请求,一个从网络通道上接受应答(启动一个单独的线程用以读取应答)。
-
如果无需等待应答,请求持续发送,接收请求的节点就可能会不堪重负。有鉴于此,一般会有一个上限,也就是一次可以有多少在途请求。任何一个节点都可以发送最大数量的请求给其它节点。一旦发出且未收到应答的请求数量达到最大值,再发送请求就不能再接收了,发送者就要阻塞住了。限制最大在途请求,一个非常简单的策略就是,用一个阻塞队列来跟踪请求。队列可以用可接受的最大在途请求数量进行初始化。一旦接收到一个请求的应答,就从队列中把它移除,为更多的请求创造空间。
-
处理失败,以及要维护顺序的保证,这些都会让实现变得比较诡异。比如,有两个在途请求。第一个请求失败,然后,重试了,服务器在重试的第一个请求到达服务器之前,已经把第二个请求处理了。服务器需要有一些机制,确保拒绝掉乱序的请求。否则,如果有失败和重试的情况,就会存在消息重排序的风险。
class RequestLimitingPipelinedConnection{
private final Map<InetAddressAndPort, ArrayBlockingQueue<RequestOrResponse>> inflightRequests = new ConcurrentHashMap<>();
private int maxInflightRequests = 5;
public void send(InetAddressAndPort to, RequestOrResponse request) throws InterruptedException {
ArrayBlockingQueue<RequestOrResponse> requestsForAddress = inflightRequests.get(to);
if (requestsForAddress == null) {
requestsForAddress = new ArrayBlockingQueue<>(maxInflightRequests);
inflightRequests.put(to, requestsForAddress);
}
requestsForAddress.put(request);
}
private void consume(SocketRequestOrResponse response) {
Integer correlationId = response.getRequest().getCorrelationId();
Queue<RequestOrResponse> requestsForAddress = inflightRequests.get(response.getAddress());
RequestOrResponse first = requestsForAddress.peek();
if (correlationId != first.getCorrelationId()) {
throw new RuntimeException("First response should be for the first request");
}
requestsForAddress.remove(first);
responseConsumer.accept(response.getRequest());
}
}
单一更新队列(Singular Update Queue)
问题
有多个并发客户端对状态进行更新时,我们需要一次进行一个变化,这样才能保证安全地进行更新。考虑一下预写日志(Write-Ahead Log)模式。即便有多个并发的客户端在尝试写入,我们也要一次处理一项。通常来说,对于并发修改,常用的方式是使用锁。但是如果待执行的任务比较耗时,比如,写入一个文件,那阻塞其它调用线程,直到任务完成,这种做法可能会给这个系统的吞吐和延迟带来严重的影响。在维护一次处理一个的这种执行的保障时,有效利用计算资源是极其重要的。
解决方案
实现一个工作队列,以及一个工作在这个队列上的单一线程。多个并发客户端可以将状态变化提交到这个队列中。但是,只有一个线程负责状态的改变。
class RequestWrapper<Req, Res> {
private final CompletableFuture<Res> future;
private final Req request;
public RequestWrapper(Req request) {
this.request = request;
this.future = new CompletableFuture<Res>();
}
public CompletableFuture<Res> getFuture() { return future; }
public Req getRequest() { return request; }
public void complete(Res response) {
future.complete(response);
}
public void completeExceptionally(Exception e) {
e.printStackTrace();
getFuture().completeExceptionally(e);
}
}
public class SingularUpdateQueue<Req, Res> extends Thread implements Logging {
private ArrayBlockingQueue<RequestWrapper<Req, Res>> workQueue
= new ArrayBlockingQueue<RequestWrapper<Req, Res>>(100);
private Function<Req, Res> handler;
private volatile boolean isRunning = false;
public CompletableFuture<Res> submit(Req request) {
try {
var requestWrapper = new RequestWrapper<Req, Res>(request);
workQueue.put(requestWrapper);
return requestWrapper.getFuture();
}
catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public void run() {
isRunning = true;
while(isRunning) {
Optional<RequestWrapper<Req, Res>> item = take();
item.ifPresent(requestWrapper -> {
try {
Res response = handler.apply(requestWrapper.getRequest());
requestWrapper.complete(response);
} catch (Exception e) {
requestWrapper.completeExceptionally(e);
}
});
}
}
private Optional<RequestWrapper<Req, Res>> take() {
try {
return Optional.ofNullable(workQueue.poll(300, TimeUnit.MILLISECONDS));
} catch (InterruptedException e) {
return Optional.empty();
}
}
public void shutdown() {
this.isRunning = false;
}
}
队列的选择
-
ArrayBlockingQueue(Kafka 请求队列使用) 正如其名字所示,这是一个以数组为后端的阻塞队列。当需要创建一个固定有界的队列时,就可以使用它。一旦队列填满,生产端就阻塞。它提供了阻塞的背压方式,如果消费者慢和生产者快,它就是适用的。
-
LinkedBlockingDeque(Zookeeper 和 Kafka 应答队列使用) 如果不阻塞生产者,而且需要的是一个无界队列,它是最有用的。选择它,我们需要谨慎,因为如果没有实现背压技术,队列可能会很快填满,持续地消耗掉所有的内存。
-
RingBuffer(LMAX Disruptor 使用) 正如 LMAX Disruptor 所讨论的,有时,任务处理是延迟敏感的。如果使用 ArrayBlockingQueue 在不同的处理阶段复制任务,延迟会增加,在一些情况下,这是无法接受的。在这些情况下,就可以使用 RingBuffer 在不同的阶段之间传递任务。
背压
工作队列用于在线程间通信,所以,背压是一个重要的关注点。如果消费者很慢,而生产者很快,队列就可能很快填满。除非采用了一些预防措施,否则,如果大量的任务填满队列,内存就会耗光。通常来说,队列是有界的,如果队列满了,发送者就会阻塞。
其它考量
- 任务链
- 调用外部的服务
分段日志(Segmented Log)
问题
当在启动时读日志的时候,单个日志文件随着时间会越来越大,成为性能瓶颈。旧日志要定时清理,要在单个大日志文件中清楚处理是非常困难的。
解决方案
使用日志分段,这里需要有个容易的方式来将日志逻辑偏移(或者日志序列号)映射到日志分段文件。下面两种方式可以实现:
- 通过相同的前缀和偏移量(或是日志序列号)生成每个分段日志名称
- 每个日志序列号分隔为两个部分,文件的文件和事务偏移量
状态监控(State Watch)
问题
客户端会对服务器上特定值的变化感兴趣。如果客户端要持续不断地轮询服务器,查看变化,它们就很难构建自己的逻辑。如果客户端与服务器之间打开许多连接,监控变化,服务器会不堪重负。
解决方案
让客户端将自己感兴趣的特定状态变化注册到服务器上。状态发生变化时,服务器会通知感兴趣的客户端。客户端同服务器之间维护了一个单一 Socket 通道(Single Socket Channel)。服务器通过这个通道发送状态变化通知。客户端可能会对多个值感兴趣,如果每个监控都维护一个连接的话,服务器将不堪重负。因此,客户端需要使用请求管道(Request Pipeline)。
客户端实现
ConcurrentHashMap<String, Consumer<WatchEvent>> watches = new ConcurrentHashMap<>();
public void watch(String key, Consumer<WatchEvent> consumer) {
watches.put(key, consumer);
sendWatchRequest(key);
}
private void sendWatchRequest(String key) {
requestSendingQueue.submit(new RequestOrResponse(RequestId.WatchRequest.getId(),
JsonSerDes.serialize(new WatchRequest(key)),
correlationId.getAndIncrement()));
}
this.pipelinedConnection = new PipelinedConnection(address, requestTimeoutMs, (r) -> {
logger.info("Received response on the pipelined connection " + r);
if (r.getRequestId() == RequestId.WatchRequest.getId()) {
WatchEvent watchEvent = JsonSerDes.deserialize(r.getMessageBodyJson(), WatchEvent.class);
Consumer<WatchEvent> watchEventConsumer = getConsumer(watchEvent.getKey());
watchEventConsumer.accept(watchEvent);
lastWatchedEventIndex = watchEvent.getIndex(); //capture last watched index, in case of connection failure.
}
completeRequestFutures(r);
});
服务端实现
private Map<String, ClientConnection> watches = new HashMap<>();
private Map<ClientConnection, List<String>> connection2WatchKeys = new HashMap<>(); //删除conntion时方便查找对应的路径
public void watch(String key, ClientConnection clientConnection) {
logger.info("Setting watch for " + key);
addWatch(key, clientConnection);
}
private synchronized void addWatch(String key, ClientConnection clientConnection) {
mapWatchKey2Connection(key, clientConnection);
watches.put(key, clientConnection);
}
private void mapWatchKey2Connection(String key, ClientConnection clientConnection) {
List<String> keys = connection2WatchKeys.get(clientConnection);
if (keys == null) {
keys = new ArrayList<>();
connection2WatchKeys.put(clientConnection, keys);
}
keys.add(key);
}
public void close(ClientConnection connection) {
removeWatches(connection);
}
private synchronized void removeWatches(ClientConnection clientConnection) {
List<String> watchedKeys = connection2WatchKeys.remove(clientConnection);
if (watchedKeys == null) {
return;
}
for (String key : watchedKeys) {
watches.remove(key);
}
}
private synchronized void notifyWatchers(SetValueCommand setValueCommand, Long entryId) {
if (!hasWatchesFor(setValueCommand.getKey())) {
return;
}
String watchedKey = setValueCommand.getKey();
WatchEvent watchEvent = new WatchEvent(watchedKey,
setValueCommand.getValue(),
EventType.KEY_ADDED, entryId);
notify(watchEvent, watchedKey);
}
private void notify(WatchEvent watchEvent, String watchedKey) {
List<ClientConnection> watches = getAllWatchersFor(watchedKey);
for (ClientConnection pipelinedClientConnection : watches) {
try {
String serializedEvent = JsonSerDes.serialize(watchEvent);
getLogger().trace("Notifying watcher of event "
+ watchEvent +
" from "
+ server.getServerId());
pipelinedClientConnection
.write(new RequestOrResponse(RequestId.WatchRequest.getId(),
serializedEvent));
} catch (NetworkException e) {
removeWatches(pipelinedClientConnection); //remove watch if network connection fails.
}
}
}
分级监听
能在父节点或键的前缀设置监听。任何变化都是触发在父节点上的子节点的监听。对于每个事件,一致性核心要遍历路径检查如果这些在父路径上设置了监听,就要给这些监听发送事件。
List<ClientConnection> getAllWatchersFor(String key) {
List<ClientConnection> affectedWatches = new ArrayList<>();
String[] paths = key.split("/");
String currentPath = paths[0];
addWatch(currentPath, affectedWatches);
for (int i = 1; i < paths.length; i++) {
currentPath = currentPath + "/" + paths[i];
addWatch(currentPath, affectedWatches);
}
return affectedWatches;
}
private void addWatch(String currentPath, List<ClientConnection> affectedWatches) {
ClientConnection clientConnection = watches.get(currentPath);
if (clientConnection != null) {
affectedWatches.add(clientConnection);
}
}
因为要调用的函数映射存储在键前缀中,它要遍历所有层来查找这个函数给接收到事件的客户端调用是很重要的。另一种方法是将事件触发的路径与事件一起发送,这样客户端就知道是哪个监听事件被发送。
处理连接异常
客户端需要告诉服务器它最近接受到的事件,客户端当重启监听的时候就会发送最近接受到的事件号。服务器会预期的发送它从该事件号开始记录的所有事件。
从键值存储派生事件
当客户端重新建立对服务器的连接,它能再次设置监听并且发送最近的变更编号。服务器就会将它与存储的值比较,如果它比客户端发送的要大,它就会重新发送事件给客户端。从键值存储区派生事件可能有点尴尬,因为需要猜测事件。它可能会丢失一些事件。举个例子,如果这个键被创建然后删除,正当这个时候客户端断开连接了,那么这个创建的事件就会丢失。
zookeeper 里的监听默认是一次性的。一旦事件被触发,客户端需要再次设置监听,如果它们想要一起接收事件的话。在再次设置监听之前会有一些事件会丢失,所以客户端需要确保读取他们最近的状态,以至他们不会丢失任何更新。
存储历史事件
保留过去事件的历史记录以及从事件历史中回复客户端是很容易的。使用这个方法的问题是事件历史需要限制,比如 1000 个事件。如果客户端长时间断开连接,它可能丢失超过 1000 个事件窗口的事件。
Write-Ahead Log(预写日志)
问题
即使是服务器机器存储数据失败的情况下也需要持久化的强力保证。一旦服务器同意执行一个操作,那它就应该这么做,甚至是在它失败以及重启丢失了所有内存状态。
解决方案
存储每个状态作为命令以文件的形式存储在硬盘中。为按顺序追加的每个服务器进程维护一个日志。单个日志它是有序追加的,它简化了在重启和随后的在线操作的日志处理(当日志以新命令追加时)。每个日志条目都给定一个唯一标识符。这个唯一的日志标识有助于在一些其它日志像分段日志操作或使用低水位线标记的日志清除。日志更新能通过使用单更新队列实现。
版本值(Versioned Value)
问题
分布式系统中,节点需要能够知道键的哪个值是最新的。有时他们需要知道过去的值,以便能够正确地对值的变化作出反应。
解决方案
为每个值都存储一个版本值。这个版本编号在每次更新的时候自增。它允许每次更新都转换为新的写操作,而不会阻塞读操作。客户端能通过指定的版本号读取历史值。
class ReplicatedKVStore{
int version = 0;
MVCCStore mvccStore = new MVCCStore();
@ovveride
public CompletableFuture<Response> put(String key, String value) {
return server.propose(new SetValueCommand(key, value));
}
private Response applySetValueCommand(SetValueCommand setValueCommand) {
getLogger().info("Setting key value " + setValueCommand);
version = version + 1;
mvccStore.put(new VersionedKey(setValueCommand.getKey(), version), setValueCommand.getValue());
Response response = Response.success(version);
return response;
}
};
写流程

读流程

多个版本读
class IndexedMVCCStore{
public class IndexedMVCCStore {
NavigableMap<String, List<Integer>> keyVersionIndex = new TreeMap<>();
NavigableMap<VersionedKey, String> kv = new TreeMap<>();
ReadWriteLock rwLock = new ReentrantReadWriteLock();
int version = 0;
public int put(String key, String value) {
rwLock.writeLock().lock();
try {
version = version + 1;
kv.put(new VersionedKey(key, version), value);
updateVersionIndex(key, version);
return version;
} finally {
rwLock.writeLock().unlock();
}
}
private void updateVersionIndex(String key, int newVersion) {
List<Integer> versions = getVersions(key);
versions.add(newVersion);
keyVersionIndex.put(key, versions);
}
private List<Integer> getVersions(String key) {
List<Integer> versions = keyVersionIndex.get(key);
if (versions == null) {
versions = new ArrayList<>();
keyVersionIndex.put(key, versions);
}
return versions;
}
}
public List<String> getRange(String key, final int fromRevision, int toRevision) {
rwLock.readLock().lock();
try {
List<Integer> versions = keyVersionIndex.get(key);
Integer maxRevisionForKey = versions.stream().max(Integer::compareTo).get();
Integer revisionToRead = maxRevisionForKey > toRevision ? toRevision : maxRevisionForKey;
SortedMap<VersionedKey, String> versionMap = kv.subMap(new VersionedKey(key, revisionToRead), new VersionedKey(key, toRevision));
getLogger().info("Available version keys " + versionMap + ". Reading@" + fromRevision + ":" + toRevision);
return new ArrayList<>(versionMap.values());
} finally {
rwLock.readLock().unlock();
}
}
}
版本向量(Version Vector)
问题
如果多服务器允许更新相同的 key,那么在跨多个副本之间的并发更新值的操作检测是非常重要的。
解决方案
每个键都是通过版本向量关联的,它负责维护每个集群节点一个数字。本质上,版本向量是一组计数器,每个节点一个。三个节点(蓝、绿、黑)的版本向量看起来应该是 [blue: 43, green: 54, black: 12]。每当一个节点进行内部更新时,它就会更新自己的计数器,所以 green 节点中的更新会将向量更改为 [blue:43,green:55,black:12]。无论两个节点何时通信,它们都会同步它们的矢量戳(vector stamps),从而让它们能检测同一个时刻的任何更新。
class VersionVector{
private final TreeMap<String, Long> versions;
public VersionVector() {
this(new TreeMap<>());
}
public VersionVector(TreeMap<String, Long> versions) {
this.versions = versions;
}
public VersionVector increment(String nodeId) {
TreeMap<String, Long> versions = new TreeMap<>();
versions.putAll(this.versions);
Long version = versions.get(nodeId);
if(version == null) {
version = 1L;
} else {
version = version + 1L;
}
versions.put(nodeId, version);
return new VersionVector(versions);
}
}
比较版本向量
通过比较每个节点的版本号来比较版本向量。如果两个版本向量都具有相同集群节点的版本号,并且每个版本号都高于另一个向量中的版本号,则认为这个版本向量高于另一个,反之亦然。如果两个向量的版本号都不高,或者它们的版本号适用于不同的集群节点,则认为它们是并发的
public enum Ordering {
Before,
After,
Concurrent
}
class VersionVector{
// 这段代码是 Voldermort 的 VectorClock 比较实现
// https://github.com/voldemort/voldemort/blob/master/src/java/voldemort/versioning/VectorClockUtils.java
public static Ordering compare(VersionVector v1, VersionVector v2) {
if(v1 == null || v2 == null)
throw new IllegalArgumentException("Can't compare null vector clocks!");
// We do two checks: v1 <= v2 and v2 <= v1 if both are true then
// 检查两项:v1 <= v2 和 v2 <= v1,两个都为真
boolean v1Bigger = false;
boolean v2Bigger = false;
SortedSet<String> v1Nodes = v1.getVersions().navigableKeySet();
SortedSet<String> v2Nodes = v2.getVersions().navigableKeySet();
// 取 v1,v2 节点交集
SortedSet<String> commonNodes = getCommonNodes(v1Nodes, v2Nodes);
// 如果 v1 的节点要比共同的节点多
// 即 v1 有 v2 没有的时钟
if(v1Nodes.size() > commonNodes.size()) {
v1Bigger = true;
}
// 如果 v2 的节点要比共同的节点多
// 即 v2 有 v1 没有的时钟
if(v2Nodes.size() > commonNodes.size()) {
v2Bigger = true;
}
// 比较相同的部分
for(String nodeId: commonNodes) {
// no need to compare more
if(v1Bigger && v2Bigger) {
break;
}
long v1Version = v1.getVersions().get(nodeId);
long v2Version = v2.getVersions().get(nodeId);
if(v1Version > v2Version) {
v1Bigger = true;
} else if(v1Version < v2Version) {
v2Bigger = true;
}
}
/*
* 这是它们相等的情况. 有意识的返回 BEFORE,
* 这样我们将返回一个 ObsoleteVersionException,用于使用相同的时钟进行在线写操作。
*/
if(!v1Bigger && !v2Bigger)
return Ordering.Before;
/* 这种情况下,v1 是 v2 的后继时钟(successor clock) */
else if(v1Bigger && !v2Bigger)
return Ordering.After;
/* 这种情况下,v2 是 v1 的后继时钟(successor clock) */
else if(!v1Bigger && v2Bigger)
return Ordering.Before;
/* 这是两个时钟并行的情况 */
else
return Ordering.Concurrent;
}
private static SortedSet<String> getCommonNodes(SortedSet<String> v1Nodes, SortedSet<String> v2Nodes) {
// 获取 v1 v2 都有的时钟 clocks(nodesIds) 集合
SortedSet<String> commonNodes = Sets.newTreeSet(v1Nodes);
commonNodes.retainAll(v2Nodes);
return commonNodes;
}
public boolean descents(VersionVector other) {
return other.compareTo(this) == Ordering.Before;
}
}
在键值存储中使用版本向量
 在无leader复制方案中,客户端或协调器节点选择该节点并基于该键写入数据。版本向量基于 key 映射到的主集群节点进行更新。将具有相同版本向量的值复制到其他集群节点上进行复制。如果映射到 key 的群集节点不可用,则选择下一个节点。版本向量只对保存该值的第一个集群节点递增(主要行为就是自增版本号),所有其他节点保存数据副本。
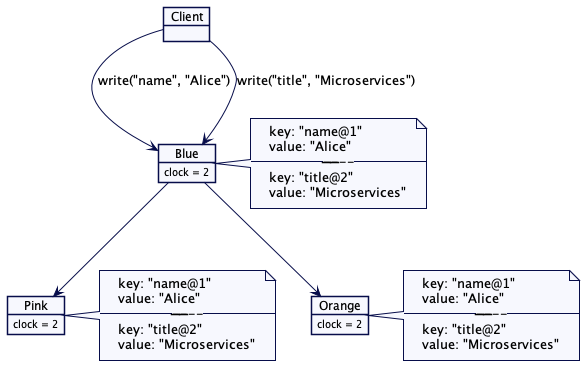
在无leader复制方案中,客户端或协调器节点选择该节点并基于该键写入数据。版本向量基于 key 映射到的主集群节点进行更新。将具有相同版本向量的值复制到其他集群节点上进行复制。如果映射到 key 的群集节点不可用,则选择下一个节点。版本向量只对保存该值的第一个集群节点递增(主要行为就是自增版本号),所有其他节点保存数据副本。
 从上图可以看出,不同的客户端可以在不同的节点上更新相同的 key,例如当客户端无法到达特定的节点时。这就产生了一种情况,不同的节点有不同的值,这些值根据它们的版本向量被认为是“并发的”。因此,当版本被认为是并发的时候,基于版本向量的存储为任何 key 保留多个版本。
从上图可以看出,不同的客户端可以在不同的节点上更新相同的 key,例如当客户端无法到达特定的节点时。这就产生了一种情况,不同的节点有不同的值,这些值根据它们的版本向量被认为是“并发的”。因此,当版本被认为是并发的时候,基于版本向量的存储为任何 key 保留多个版本。
class VersionVectorKVStore{
public void put(String key, VersionedValue newValue) {
List<VersionedValue> existingValues = kv.get(key);
if (existingValues == null) {
existingValues = new ArrayList<>();
}
rejectIfOldWrite(key, newValue, existingValues);
List<VersionedValue> newValues = merge(newValue, existingValues);
kv.put(key, newValues);
}
//如果 newValue 要比已存在的版本值旧则拒绝
private void rejectIfOldWrite(String key, VersionedValue newValue, List<VersionedValue> existingValues) {
for (VersionedValue existingValue : existingValues) {
if (existingValue.descendsVersion(newValue)) {
throw new ObsoleteVersionException("Obsolete version for key '" + key
+ "': " + newValue.versionVector);
}
}
}
//将 newValue 与现有值合并。删除版本低于 newValue 的值。
//如果已存在的值既不在 newValue 之前也不在 newValue 之后(并发)。它会被保留下来
private List<VersionedValue> merge(VersionedValue newValue, List<VersionedValue> existingValues) {
List<VersionedValue> retainedValues = removeOlderVersions(newValue, existingValues);
retainedValues.add(newValue);
return retainedValues;
}
private List<VersionedValue> removeOlderVersions(VersionedValue newValue, List<VersionedValue> existingValues) {
List<VersionedValue> retainedValues = existingValues
.stream()
.filter(v -> !newValue.descendsVersion(v)) //保留不直接由newValue控制(dominated)的版本
.collect(Collectors.toList());
return retainedValues;
}
}
解决冲突
如果从不同的副本返回多个版本,则能通过向量时钟比较可以检测到最新的值。
class ClusterClient{
public List<VersionedValue> get(String key) {
List<Integer> allReplicas = findReplicas(key);
List<VersionedValue> allValues = new ArrayList<>();
for (Integer index : allReplicas) {
ClusterNode clusterNode = clusterNodes.get(index);
List<VersionedValue> nodeVersions = clusterNode.get(key);
allValues.addAll(nodeVersions);
}
return latestValuesAcrossReplicas(allValues);
}
private List<VersionedValue> latestValuesAcrossReplicas(List<VersionedValue> allValues) {
List<VersionedValue> uniqueValues = removeDuplicates(allValues);
return retainOnlyLatestValues(uniqueValues);
}
private List<VersionedValue> retainOnlyLatestValues(List<VersionedValue> versionedValues) {
for (int i = 0; i < versionedValues.size(); i++) {
VersionedValue v1 = versionedValues.get(i);
versionedValues.removeAll(getPredecessors(v1, versionedValues));
}
return versionedValues;
}
private List<VersionedValue> getPredecessors(VersionedValue v1, List<VersionedValue> versionedValues) {
List<VersionedValue> predecessors = new ArrayList<>();
for (VersionedValue v2 : versionedValues) {
if (!v1.sameVersion(v2) && v1.descendsVersion(v2)) {
predecessors.add(v2);
}
}
return predecessors;
}
private List<VersionedValue> removeDuplicates(List<VersionedValue> allValues) {
return allValues.stream().distinct().collect(Collectors.toList());
}
}
当有并发更新时,仅仅基于版本向量进行冲突解决是不够的。因此,允许客户端提供特定于应用程序的冲突解决程序是很重要的。客户端可以在读取值时提供冲突解决程序。
最新写入获胜(Last Write Wins;LWW)解决冲突
对于键值存储有时客户端更喜欢根据时间戳解决冲突,尽管存在跨服务器时间戳的已知问题,但这种方法的简便性使其成为客户机的首选,即使存在由于跨服务器时间戳问题而丢失某些更新的风险(关于时间戳解决冲突的问题详见兰伯特时钟(Lamport Clock))
读修复
虽然允许任何集群节点接受写请求可以提高可用性,但重要的是最终所有副本都具有相同的数据。常见的修复副本的方法是在客户端读取数据时发生。当冲突解决后,还可以检测哪些节点有较早的版本。具有较旧版本的节点可以从客户端读取请求处理的发送最新版本。这叫做读修复。

点分版本向量(Dotted version vector)
https://riak.com/posts/technical/vector-clocks-revisited-part-2-dotted-version-vectors/index.html
参考资料
https://github.com/pwcrab/Patterns-of-Distributed-Systems/tree/master