第一章:线程安全的对象生命周期管理
构造函数与多线程
构造函数做到多线程安全,唯一要求是在构造期间不要泄露this指针,即:
- 在构造期间不要注册任何回调函数
- 不要在构造期间把this指针传给跨线程对象
- 即使在构造函数最后一行也不可以,因为此类可能是基类
通常使用方式是二段式构造,即构造函数+initilalize()函数
析构函数遇到多线程存在问题
- 其他线程函数是不是在访问即将析构对象?
- 如果保证在执行成员函数时期对象会不会被另一个线程析构?
- 在执行成员函数时,其析构函数会不会执行到一半
作为数据成员的mutex不能保护析构函数,因为作为成员变量的mutex其生命周期与对象的生命周期相同,析构操作可能发生在对象身亡之时和身亡之后;其次,对于基类,当调用起析构函数时,子类已经析构了,则mutex不能保证整个析构过程
解决上述的方案是使用shared_ptr
神奇shared_ptr
出现内存错误的几个方面:
- 缓冲区溢出:使用std::vector
/std::string或者自定义的Buffer class来管理缓冲区 - 野指针:使用shared_ptr
- 重复释放:使用scoped_ptr
- 内存泄漏:使用scoped_ptr
- 不配对的new[]/delete: 把new[]替换为std::vector或者scoped_array
再论shared_ptr的线程安全
shared_ptr不是100%线程安全的,但是他的引用计数是安全无锁的,但是对象的读写则不是。shared_ptr的线程安全和内建类型是一样的,即:
- 一个shared_ptr对象实体可以被多个线程同时读取
- 两个shared_ptr对象可以被2个线程同时写入(析构算是写入)
- 如果多个线程同时读取一个shared_ptr对象,则需要加锁(在多核系统上可以考虑使用spin lock)
以上是shared_ptr对象本身线程安全,不是它管理的对象的线程安全级别
shared_ptr作为函数参数传递时不复制,用reference to const作为参数类型即可
shared_ptr技术与陷阱
意外延长对象的声明周期
shared_ptr允许拷贝构造函数和赋值函数,如果一不小心遗留了一个拷贝,那么对象的生命周期可能就会延长。比如使用std::bind时如果实参为shared_ptr,则实参会被拷贝一份。
函数参数
作为函数参数时,由于需要引用计数,因此拷贝的成本比原始指针要高,因此一般使用referenc to const作为参数类型
析构函数在创建的时候被捕获
- shard_ptr
可以持有任何的对象,而且能安全的释放 - shared_ptr对象可以跨模块边界
- 二进制兼容,即使对象的大小变了,旧的client仍然可以使用新的动态库
- 析构函数可以定制
析构所在的线程
最后一个指向对象的shared_ptr离开其作用域时,该对象会在同一个线程析构掉,未必是对象创建的线程
现成的RAII handle
shared_ptr作为现成的handle对象,需要避免循环引用,通常做法是owner持有指向child的shared_ptr, child持有指向owner的weak_ptr
对象池
当时使用std::bind并且传入this指针时,需要注意该对象是否有可能析构。为了解决这个问题引入enable_shared_from_this, 该类继承enable_shared_from_this并且使用shared_from_this()代替this指针
第二章:线程同步精要
互斥锁
只使用非递归的mutex
死锁
- 单线程死锁:抽象出无锁调用的公共方法
- 多线程死锁
条件变量
对于wait端:
- 必须与mutex一起使用,布尔表达式的读写需要mutex保护
- 在mutex上锁的时候才能调用wait
- 把判断布尔条件和wait()放到while循环中
对于signal/broadcast端:
- 不一定要在mutex已上锁的情况下调用signal
- 在single之前需要修改布尔表达式
- 修改布尔表达式通常需要mutex保护
- broadcast表示状态变化,signal表示自愿可用
不要使用读写锁和信号量
见到一个数据读多写少,使用读写锁未必正确:
- 在持有read lock的情况下,有可能在维护阶段修改了其中的状态
- 从性能角度来看,在read lock加锁阶段的开销不会比mutex lock小,因为其需要维护reader数据
- read lock有可能提升为write lock,也有可能不提升
- read lock可重入,但是write lock不可重入,为了防止write lock饥饿,write lock会阻塞read lock,导致read lock在重入的时候死锁(旧的read lock没有释放锁,又有write lock存在,导致新的read lock不能加锁)
信号量存在的问题:
- semaphore has no notion of ownership
- 其有自己的计数值,与代码的数据结构冲突,可能出错
线程安全的Singleton实现
template<typename T>
class Singleton : boost::noncopyable
{
public:
static T& instance()
{
pthread_once(&ponce_, &Singleton::init);//只被初始化一次
return *value_;
}
private:
Singleton();
~Singleton();
static void init()
{
value_ = new T();
}
static pthread_once_t ponce_;
static T* value_;
};
template<typename T>
pthread_once_t Singleton::ponce_ = PTHREAD_ONCE_INIT;
template<typename T>
T* Singleton<T>::value_ = NULL;
c++11内存模型
sleep不是同步原语
生产代码中等待可分为2种:
- 等待资源可用,等待select、epoll_wait或者等待条件变量上
- 等待进入临界区(等待mutex上),通常时间比较短
借shared_ptr实现copy-on-write
- 对于write端,进入临界区内之后,如果shared_ptr的引用计数为1,则直接修改;如果引用不为1,则reset shared_ptr并new新的内存空间复制给shared_ptr,最后退出临界区
- 对于read端,进入临界区内之后,拷贝shared_ptr,退出临界区。在临界区外进行读操作
第三章:多线程服务器的使用场合与常用编程模型
进程与线程
可以把进程比喻成一个”人”,每个人都有自己的记忆(memory),人与人通过谈话(消息传递)来交流,谈话既可以面谈(同一台服务器),也可以在电话里谈(不同服务器,有网络通信)。面谈和电话谈的区别在于面谈可以立即知道对方是否死了,而电话谈只能通过周期性的心跳来判断对方是不是活着。 然后可以思考:
| 容错 | 万一有人死了 |
| 扩容 | 中途有新人嫁过来 |
| 负载均衡 | 把甲的活儿挪给已做 |
| 退休 | 甲要修复bug,先别派新任务,等他做完手上的事情就把他重启 |
线程的特点是共享地址空间,从而可以高效地共享数据。一台机器上多的进程可以高效的共享代码段,但不能共享数据。
单线程服务器常用的编程模型
基于事件驱动的编程模型,要求时间回调函数必须是非阻塞的;对于涉及到网络io请求的响应式协议,容易割裂业务逻辑,使其散布于多个回调函数中。
多线程服务器的程勇编程模型
one loop per thread
在此种模型下,程序每个IO线程有一个event loop,用于处理读写和定时事件。
好处:
- 线程数目基本固定,可以在程序启动时设置,不会频繁创建与销毁
- 可以方便在线程间调配负载(数据量大的connection可以独占一个线程,实时性要求高的connection可以独占一个线程)
- IO事件发生的线程是固定的,同一个TCP连接不必考虑事件并发
推荐模式
one(event) loop per thread + thread pool
- event loop用作IO多路复用,配合非阻塞io和定时器
- thread pool用来做计算,可以是任务队列或者生产消费队列
进程间通信只用TCP
pipe的优缺点
- pipe在收发字节流方面,是单向的
- 进程双向通信还得开2个文件描述符,并且需要有父子进程才能使用
- pipe经典的应用场景是用来异步唤醒select调用
TCP的优缺点
- TCP通信可以跨机器,提高了scalability
- port是独占的,可以防止程序重复启动
- 可以通过tcpdump和wireshark来重现和记录
- 可以跨语言通信
- TCP是字节流协议,只能顺序读取,有写缓冲;共享内存需要a进程填好一块内存让b进程来读,基本是“停等”方式(需要考虑如果数据写到一半怎么办)
多线程服务器的适用场景
必须用单线程的场合
- 程序可能fork
- 限制程序的CPU的占有率
单线程程序的优缺点
- 简单
- 非抢占的容易发生优先级反转
适合多线程程序的场景
提高响应速度,让IO和”计算”相互重叠,降低latency。
- 有多个CPU可用
- 线程间有共享数据,如果没有共享数据,使用master+worker模型就行
- 共享数据可以修改,不是静态的常量,否则通过进程间共有shared memory就行
- 提供非均质的服务,防止优先级反转
- 有相当的计算量
- 利用异步操作
- 能scale up
- 具有可预测性
- 多线程能有效划分责任与功能
“多线程服务器的适用场景”例释与解答
- 一个多线程的进程和多个相同的单线程进程怎么取舍? 如果一次请求所访问的内存比较大,那么就使用多线程,避免CPU cache换入换出,影响性能
- 还有那些多线程的编程模型 Proactor模型可以提高吞吐,但是不能降低延迟
- 多线程程序如何让IO和”计算”相互重叠,降低latency? 把IO操作通过BlockingQueue交给别的线程去做,自己不必等待
- 多线程能降低响应时间吗? 如果设计合理,充分利用多核资源的话,可以
第五章高效的多线程日志
使用stream风格日志好处是当输出的日志级别高于语句的日志级别时,打印日志时个空操作。
功能需求
日志不能为每条消息都flush磁盘,解决方案通常有2个:
- 定义将缓冲区的日志flush到磁盘
- 每条内存中的日志消息都带有哨兵值,其值为某个函数的地址,这样通过coredump文件中查找哨兵值就能查出来尚未写入的消息
性能需求
- 时间字符串中的日期和时间两部分是缓存的
- 日志消息的前4个字段是定长的,可以避免运行期间求字符串
- 线程id预先格式化为字符串
- 每行日志消息的原文件部分在编译期计算来获得basename
多线程异步日志
第七章muduo编程示例
muduo buffer类的设计与使用
muduo的io模型
非阻塞几乎和io多路复用几乎一起使用:
- 没有人会用通过轮询的方式来检查非阻塞io是否完成,这样太浪费CPU
- 阻塞io中的read、write、accept和connect会阻塞当前线程
为什么非阻塞网络编程中应用层buffer是必须的
非阻塞io的核心思想是避免阻塞在read或者write上,io线程只能阻塞在io复用多路函数上。 使用水平触发而没有使用边缘触发的原因:
- 文件描述符比较少时,poll未必比epoll低效
- 水平除非更容易编程,以往select和poll经验都可以使用,方便切换
- 使用水平触发时读写操作不必等到出现EAGAIN,节省系统调用(边缘触发需要一次性的把缓冲区的数据读完为止,也就是一直读,直到读到EGAIN(EGAIN说明缓冲区已经空了)为止,因为这一点,边缘触发需要设置文件句柄为非阻塞)
Buffer功能需求
使用readv代替read系统调用,利用栈上临时空间避免分配过大内存导致内存浪费,同时减少了系统调用。
read会从fd当前的offset处开始读,读取完n byte后,该fd的offset会增加n byte(假设可以读取到nbyte),下一次read则从新的offset处开始读。而pread则是从指定的offset处开始读,这个offset是相对于0的一个绝对值,与fd当前的offset没有关系。read和pread的区别就是,read会改变fd的offset,而pread不会改变。 pread的实际操作类似于lseek+read,即先将offset调整到指定值,再调用read读取数据,两者的区别在于 pread是一个原子操作,从而可以保证一定是从指定的offset处开始读;另外就是pread读取完数据会恢复执行之前的offset,即pread操作前后的offset是一致的。readv则是从fd中读取数据到多个buf,buf数为iovcnt,每个buf有自己的长度(可以一样),一个buf写满(写指读出数据并保存),才接着写下一个buf,依次类推。 preadv与readv的关系,与上述read和pread的关系一样。除了文件 I/O,还有网络 I/O,read/write 也可用于网络 I/O
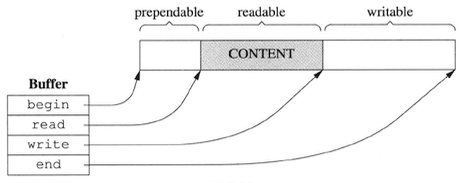
Buffer的数据结构
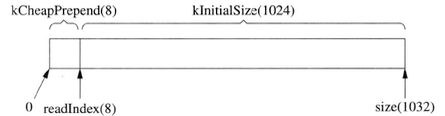
Buffer的操作
内部是一个std::vector
readIndex和wirteIndex为下标而不是指针,因为vector在自动增长扩容时指针会失效 vector::resize会调用memset,稍微有点浪费
其他设计方案
不使用std::vector
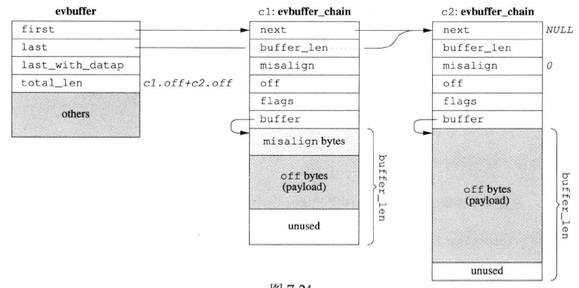
zero copy
如果对性能有极高的要求,受不了copy()与resize(),可以考虑实现分断连续的zero copy buffer,在配合gather cattor IO,基本思路是不要求数据在内存中连续。
第九章: 分布式系统工程实践
分布式系统中的心跳协议的设计
使用TCP连接作为分布式系统中进程通信方式,其好处是在进程意外退出时,操作系统会关闭进程使用的TCP socket,往对方发送FIN报文,但是还是需要应用层心跳,因为:
- 如果是因为机器崩溃或者硬件故障导致的重启,没有机会发送FIN报文
- FIN报文可能出现丢包
- 网络故障
同时使用tcp keepalive也不行,keepalive是由操作系统来发起探查的,及时进程死锁或者阻塞,操作系统也会正常首发消息。
- 一般发送周期和检查周期相同为T,timeout>T,虽然发送周期和检查周期都为T,但是无法保证每个检查周期恰好收到一条心跳,有可能一条都没有收到,通常可取timeout为2T
- 心跳消息也应包含每个进程的唯一标识以及负载状况,便于客户端做负载均衡
- 如果发送心跳的过程中有其他中断的消息进程,应该还需要在消息中加上发送时间,防止消息在中转过程中因堆积而出现的假心跳
- 要在工作线程发,不要单独起一个“心跳线程”
- 与业务消息用相同的连接,不要单独用“心跳连接”
分布式系统中的进程标识
错误做法
- ip:port
- host:pid
正确做法
ip:port:start_time:pid
第十章:C++编译链接模型精要
c++至今没有模块机制,不能使用import或者using引入依赖的库,必须使用include头文件来机械地将库的接口声明以文本替换的方式载入,重新parse一遍。存在以下2个问题:
- 头文件具有传递性,引入不必要的依赖
- 头文件是在编译时使用,库文件在运行时使用,二者的时间差可能导致二进制不兼容
C语言的编译模型及其成因
为什么C语言需要预处理
为了减少内存使用的情况实现分离编译,C语言采用“隐式函数声明”的做法,代码在使用前文未定义的函数时,编译器不需要检查函数原型,会出现连接错误而非编译错误。为了减少各个源文件的重复代码,同时提高代码的可移植性,将公共信息坐成头文件,程序include用到的头文件即可。
C语言的编译模型
由于不能将整个语法树保存在内存中,C语言按照单遍编译的方式来设计。编译器只能看到目前已经解析过的代码,但不到之后的代码。所以:
- 结构体必须先定义,才能访问其成员,否则不知道成员的类型和偏移量,不能生成目标代码
- 局部变量有需要先定义再使用,否则不知道类型已经在stack中的位置,不能生成目标代码
- 对于外部变量,编译器只需要知道类型和名字,不要其地址。在生成目标代码的地址是个空白,留给链接器去填
- 编译器看到一个函数调用时按照隐式函数声明原则,可以生成调用函数的汇编代码,但是函数的实际地址不确定,留给链接器去填
C++的编译模型
单遍编译
C++也继承了单遍编译,编译器只能根据目前看到的代码作出决策,即使读到后面的代码也不会影响前面作出的决定。
void foo(int) {
printf("foo(int);\n");
}
void bar() {
foo('a'); //调用 foo(int)
}
void foo(char) {
printf("foo(char)"); //修改foo(char)和foo(int)位置结果不一样
}
int main() {
bar();
}
向前声明
为了完成语法检查生成目标代码,编译器需要知道函数的参数个数和类型以及返回值类型,并不需要知道函数体的实现(除非是inline函数)。需要在某个源文件中定义这个函数,否则会链接错误。如果在定义的时候把函数参数类型写错了,则在生成目标的文件的时候不会报错,但是在链接的时候会报错。
以下2中情况可以向前声明:
- 定义或者声明类的指针或者引用,包括用于函数参数、返回类型、局部变量、类型成员变量
- 声明一个类为参数或者返回类型的函数,但是如果要调用这个函数就需要知道类的定义,因为需要使用拷贝构造函数和析构函数
C++链接
c++相比于c语言的连接,主要增加了两项:
- 函数重载,需要类型安全的连接(name mangling)
- vague linkage,同一个符号有多份互不冲突的定义
函数重载
返回类型不参加函数重载
inline函数
如果编译器无法展开inline函数,则每个编译单元都会生成一个inline函数的目标代码。然后链接器会从多份实现中任选一个保留,其余的会丢弃。同时编译器自动生成的class的析构函数也是inline函数。
模板
- 模板编译连接的不同之处在于,以上具有external linkage的对象通常会在多个单元被定义,链接器必须进行重复代码的消除,才可以生成正确的可执行文件。但是在-O2编译下,编译器会把短函数都inline展开。
- 对于private成员函数模板,只需要在头文件中给出声明,因为用户代码不会调用它,无法实现随意具现化,不会造成连接错误
虚函数
一个多态class的vtable应该恰好被一个目标文件定义,但是C++无法判断是不是应该在当前编译单元中生成vtable定义,所以为每个编译单元都生成vtable,交给连接器去消除重复数据。如果我们不希望vtable导致目标文件膨胀,在头文件的class定义中声明out-line 虚函数
第十一章:反思C++面向对象与虚函数
朴实的C++设计
程序库的二进制兼容
什么是二进制兼容性
在升级库文件的时候,不需要重新编译使用了这个库的可执行文件或者其他库文件,并且程序的功能不被破坏。
有哪些情况会破坏库的ABI
C++编译器ABI主要包含以下几个方面:
- 函数参数传递方式,比如:x86-64用寄存器来传函数的前4个参数
- 虚函数的调用方式,通常是vptr/vtbl机制,然后用vtabl[offset]来调用
- struct 和class的内存布局,通过偏移量来访问数据成员
- name mangling
- RTTI和异常处理的实现
编译器如何判断一个改动是不是二进制兼容的,主要看旧的头文件是不是和新版本的动态库的使用方法兼容,因为新的库必然新的头文件,现在的二进制可执行文件还是按照旧的头文件中的方式来调用。
二进制不兼容的例子:
- 定义的non-virtual函数
void foo(int),参数类型改成了double,则会出现undefined symbol错误,因为mangled name不同。但是对于virtual函数,修改其参数类型,则不会出现错误,因为虚函数的决议通过便宜量,并不是靠符号名。 - 给函数添加默认参数,现有的可执行文件无法传这个额外的参数
- 增加虚函数,会造成vtbl里面的排列变化,不考虑只在莫问增加这种技巧
- 增加默认模板类型参数,这回导致name mangling发生变化
- 增加enum的值,这会早上错误,在末尾添加除外
- 给class增加数据成员,通常是不安全的。但是如果代码里面不是通过new 构造对象,而是通过factory返回对象指针或者shared_ptr,可能是安全;或者不需要用到data member的offset,也可能是安全的
哪些做法多半是安全的
- 增加新的class
- 增加non-virtual成员函数或者static成员函数
- 修改数据成员的名称,因为二进制代码是按照偏移量来访问的
反面教材:COM
解决方法
- 采用静态链接,完全从源码编译出可执行文件
- 通过动态库的版本来管理控制兼容性
- 用pimpl技法,在头文件中只暴露non-virtual接口,并且class的大小是固定的
避免使用虚函数作为库的接口
C++程序库的作者的生存环境
对于C++库需要考虑的问题:
- 以什么方式发布?动态库还是静态库
- 以什么方式暴露接口?全局函数?还是non-virtual成员函数或者以virtual函数为接口?
虚函数作为库的接口的两大用途
- 调用
- 回调
虚函数作为接口的弊端
如果要增加新接口,同时保证二进制兼容性,实现起来比较丑陋。
假如Linux系统调用以COM方式实现
动态库接口的推荐做法
- 对于使用范围比较少的情况,在头文件和class中有意识的区分用户可见和用户不可见两部分。对于用户可见部分升级时注意二进制兼容性,对于不可见部分不必在意。
- 对于使用范围比较广的情况,使用pimpl方式。考虑多使用non-member non-friend 做为接口,不要使用虚函数;并且需要显示声明构造函数和析构函数,并且不能是inline的;在库实现中把调用转发给实现类,这部分代码都放到so中;如果需要新加函数,不需要通过继承来扩展,可以原地修改。libevent2中
struct event_base是个opaque pointer,客户端看不到其成员。
以boost::function和boost::bind取代虚函数
随着系统的演进,原来正确的决定可能变成错误的。如果一个类有很多的子类,如果想把这个class在继承树上从一个节点挪到另一个节点,可能要触及到用这个class的客户代码,以及从这个class派生出来的全部代码,牵一发而动全身。因此不采用基于继承的设计。
在实现层面,事件回调通常是通过虚函数执行,往往需要实现新派生类,这些派生类的生命周期比较模糊,难以确定。
基本用途
对程序库的影响
线程库
class Thread {
public:
typedef boost::function<void()> ThreadCalback;
Thread(ThreadCalback cb): cb_(cb){}
void start() {}
private:
void run() {
cb_();
}
ThreadCalback cb_;
};
什么时候使用继承?一般是继承boost::noncopyable或者boost::enable_shared_from_this,使用多态代替switch-case以达到简化代码的目的,这个时候数据固定,功能也完全确定(为了接口和实现分离,只会在派生类数据和功能完全固定的情况下使用)
C++经验谈
用异或来交换变量是错误的
- 同一份代码在不同的编译平台上编译之后的汇编代码可能不太一样
- 代码行数少不一定运行的快
不要重载全局::operator::new()
内存管理的基本要求
new/delete要配对
重载::operator::new的理由
- 检测代码中的内存错误
- 优化性能
- 获得内存使用的统计计数
::operator::new的2种重载方式
- 直接替换系统原有的版本
#include <new> void* operator new(std::size_t size); void operator delete(void *ptr); - 增加新的参数,调用时也提供额外的参数
void* operator new(std::size_t size, const char* file, int line); void operator delete(void* p,const char* file, int line);可以通过如下方式使用
Foo *p = new(__FILE,__LINE__) Foo;// 跟踪哪个文件哪一行代码分配了内存,一般统计内存使用状况或者检测内存错误会用这种方式
重载operator::new的困境
- 不要在library里面重载::operator::new()函数,可能会影响使用library的人
- 在主程序里面重载用处不大
解决方法:替换malloc
通过LD_PRELOAD加载so,里面有malloc和free的代替实现。
- 对于”检测内存错误”:可以用valgrind等工具实现
- 对于“统计内存使用数据”:可以用backtrace来获得函数调用栈
- 对于”内存优化”:使用tcmalloc护着TBB等内存优化器
带有符号整数的除法与余数
c99和c++11都规定商向0取整,c89和c++98规定由编译器实现
在单元测试中mock系统调用
在系统函数的依赖注入
- 借助面向对象的手段,自己实现Systemc Interface,把系统调用设计成虚函数,在运行单元测试的时候都替换成mock的对象
- 在编译和链接期间延迟绑定,声明一个中间层的namespace,把需要mock的函数做成一个library
链接期垫片
如果在程序一开始的时候没有考虑到单元测试需要mock系统调用,可以自己实现一个函数替换系统调用。在链接的时候会优先使用自己定义的函数(仅对动态链接成立;对于静态链接会报multiple definition)
typedef int(*connect_func_t) (int sockfd, const struct sockaddr *addr, socklen_t addrlen);
connect_func_t connect_func = dlsym(RTDL_NEXT, "connect");
bool mock_connect;
int mock_connect_error;
extern "C" int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen) {
if (mock_connect) {
errno = mock_connect_error;
return errno == 0 ? 0: -1;
} else {
return connect_func(sockfd, addr, addrlen);
}
}
其他做法
使用ld –warp 替换动态库中的函数
慎用匿名namespace
C语言static关键字的用法
- 用于函数内部修饰变量,表示这种变量的生存周期长于该函数。使用静态变量的函数一般不可重入,也不是线程安全的
- 用在文件级别(函数体之外),修饰变量或函数,表示该变量或者函数只有本文件可见,其他文件看不到,也范访问不到改变量或函数
C++语言的static关键字的四种用法
- 用于修饰class的数据成员,这种数据成员的声明周期大于class的对象。静态成员是每个class一份(class variable),普通成员是每个实例有一份(instance variable)
- 用于修饰class的成员函数,只能访问static变量和静态程序函数,不能访问instance variable 和methord
匿名namespace的不利之处
- 明确引用哪个匿名函数比较麻烦
- 同一个编译器,编译同一个文件,每次编译后生成的符号表可能不一样
采用有利于版本管理的代码格式
对diff友好的代码格式
- 多行注释也用//,不用 /**/
- 一行只定义一个变量
- 如果函数参数大于3个,在逗号后面换行,每个参数占一样
- 在调用函数时候,如果参数大于3个,把实参分行写
- class初始化列表也遵循一行一个
- namespace不设置缩进
对grep友好的代码风格
- 操作符重载
- static_cast与C-style static_cast
再探std::string
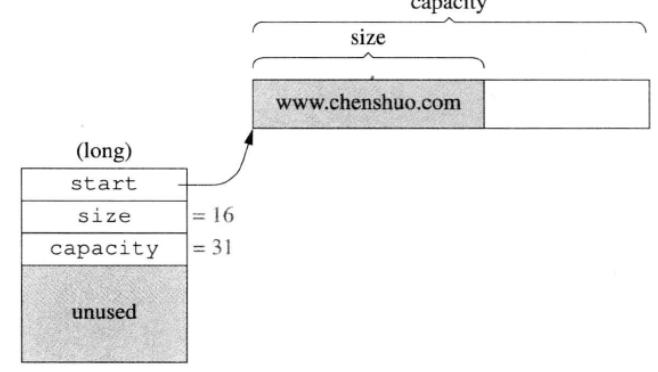
string的实现方式:
- 无特殊处理采用类似std::vector的数据结构
- 写时复制(COW)
- 短字符串优化(SSO),利用string对象本身空间来存储短字符串
以上无论哪种方式都要保存三个数据:1)字符串本身 2)字符串的长度 3)字符串的容量
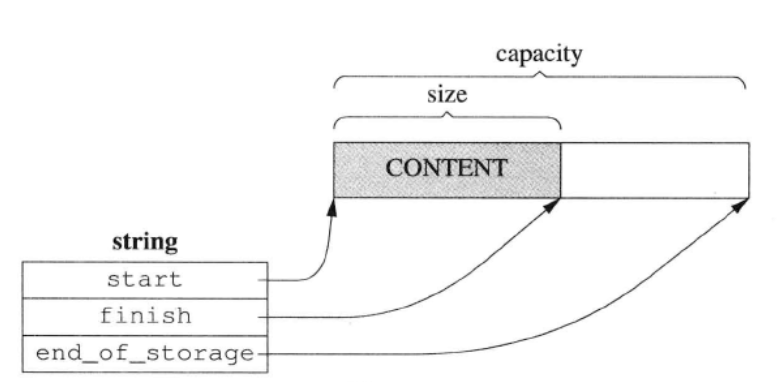
直接拷贝
class string {
public:
const_pointer data() const { return start; }
iterator begin() { return start; }
iterator end() { return end; }
size_type size() const { return end - start; }
size_type capacity() const() { return end_of_storage - start; }
private:
char* start;
char* end;
char* end_of_storage;
};
内存布局如图
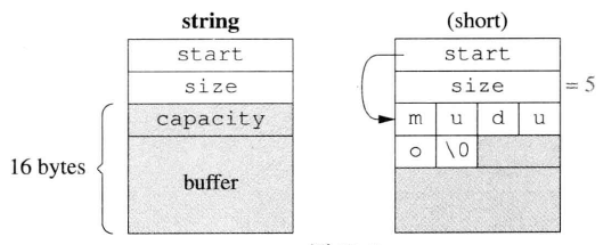
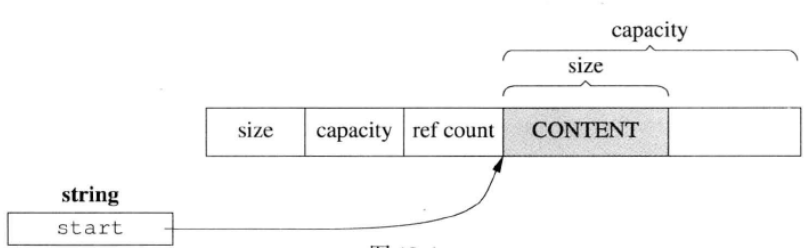
写时复制
class string {
strcut Rep {
size_t size;
size_t capacity;
size_t refcount;
char* data[1];
};
char* start;
};
拷贝字符串的复杂度是O(1),但是第一次operator[]的复杂度是O(n)
内存布局如图
短字符串优化
class string {
char *start;
size_t size;
static const int kLocalSize = 15;
union {
char buf[kLocalSize +1];
size_t capacity;
} data;
};
内存布局如图